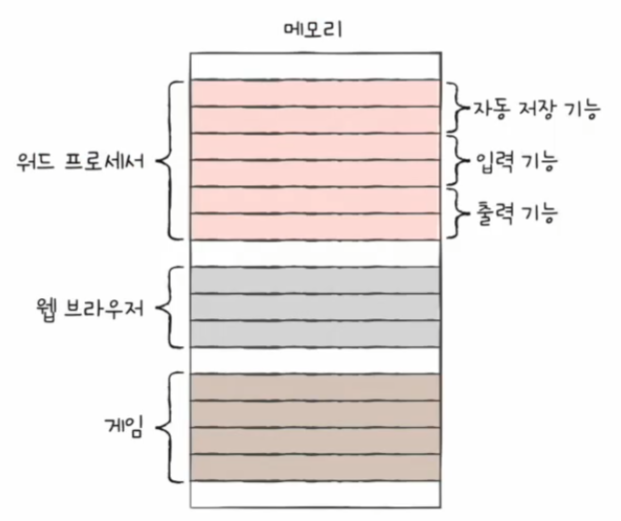
메모리와 캐시 메모리
주기억장치의 종류에는 크게 RAM과 ROM 두 가지가 있고, '메모리'라는 용어는 그중 RAM을 지칭하는 경우가 많다.
RAM의 특징과 종류
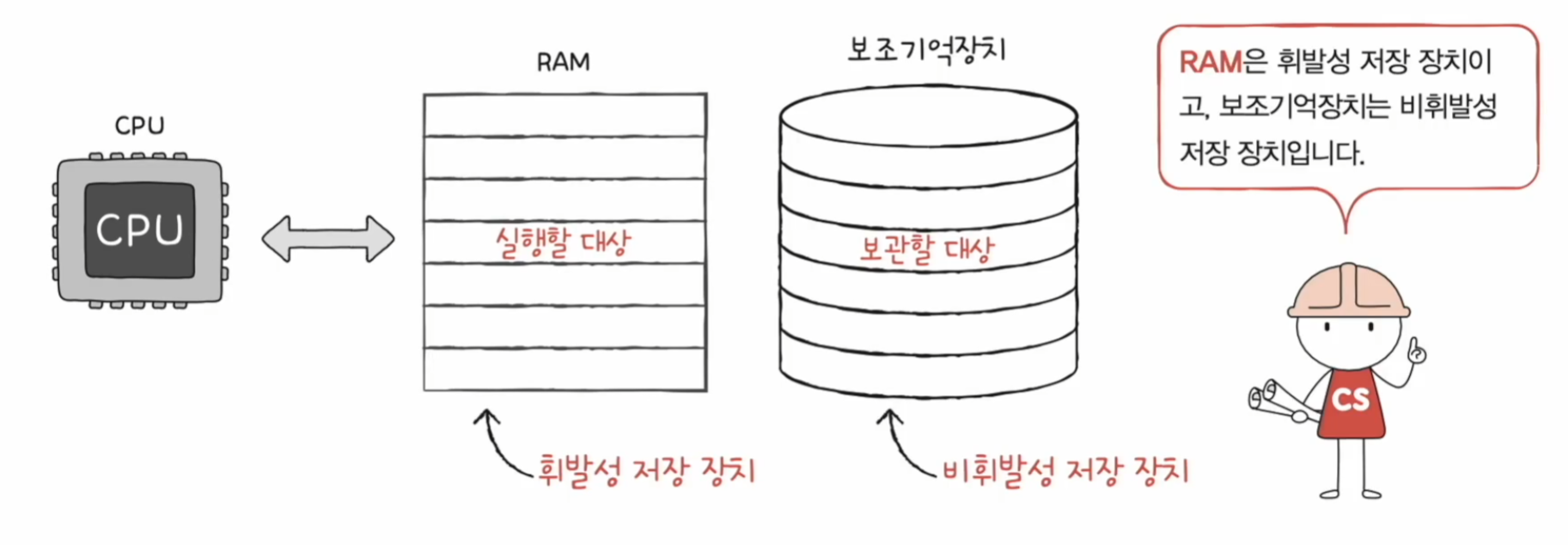
RAM은 실행할 대상을 저장한다. 하지만 RAM에 저장한 내용은 전원이 꺼지면 사라진다. 그래서 전원이 꺼져도 기억할 수 있는 보조기억장치가 필요하다.
그렇다면 RAM이 크면 뭐가 좋으며, RAM의 용량은 컴퓨터 성능에 어떠한 영향을 미칠까?
RAM의 용량과 성능
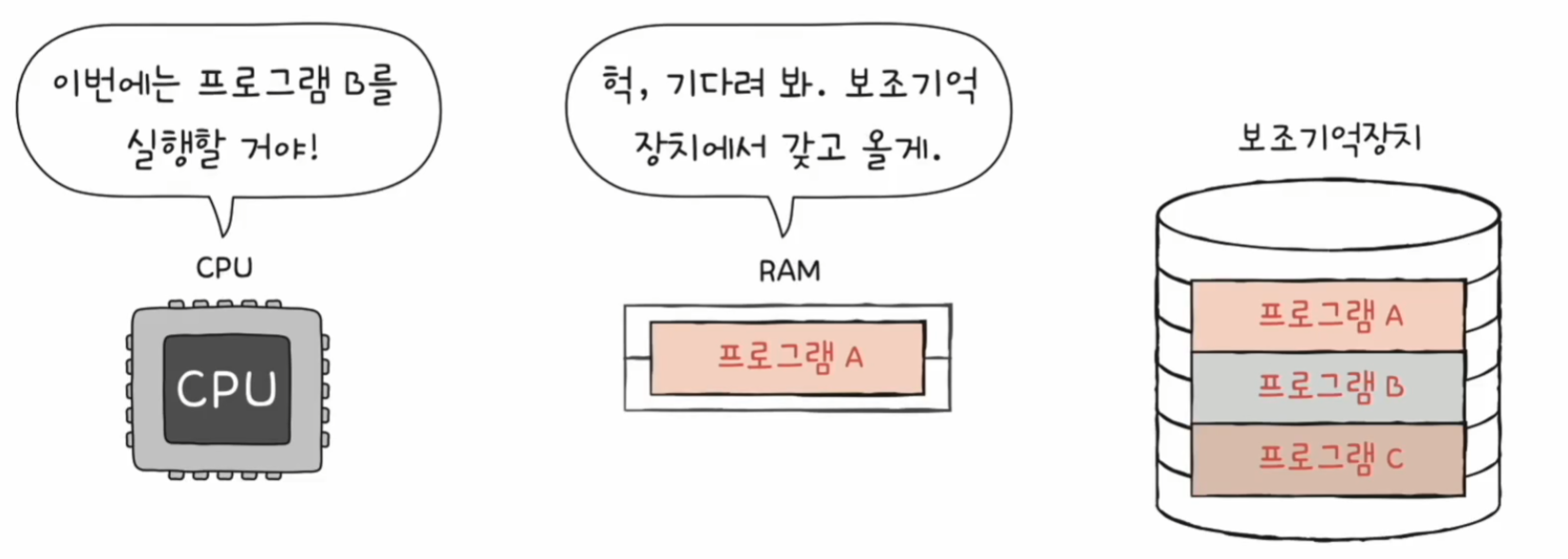
RAM의 용량이 작을경우 CPU가 다른 프로그램을 실행하려고 할 때마다 RAM은 보조기억장치에서 해당 프로그램 내용을 가져와야 한다. 따라서 CPU가 한 번에 여러 개의 프로그램을 동시에 실행할 수 있는 성능이 저하된다.

RAM의 용량이 클 경우 CPU가 한번에 여러 개의 프로그램을 동시에 실행할 수 있는 성능이 향상된다.

책장을 보조기억장치, 책상을 RAM으로 비유하면 위 그림과 같다. 책상이 크다면 많은 책들을 미리 책상에 놓고 필요할 때 볼 수 있다.
RAM의 종류
- DRAM
- SRAM
- SDRAM
- DDR SDRAM
DRAM
- Dynamic RAM
- 저장된 데이터가 동적으로 사라지는 RAM (전원이 공급되고 있어도 저장된 데이터가 점점 없어짐)
- 데이터 소멸을 막기 위해 주기적으로 재활성화해야 한다.
DRAM은 일반적으로 메모리로 사용되는 RAM이다. 그 이유는 상대적으로 소비전력이 낮고, 저렴하며, 집적도가 높아 대용량으로 설계하기 용이하기 때문이다.
SRAM
- Static RAM
- 저장된 데이터가 정적인 (사라지지 않는) RAM
- DRAM보다 일반적으로 더 빠름
SRAM은 일반적으로 캐시 메모리에서 사용되는 RAM이다. 그 이유는 상대적으로 소비전력이 높고 비싸며, 집적도가 낮기 때문이다. 따라서 대용량으로 설계할 필요는 없으나 빨라야 하는 장치에 사용한다.
DRAM vs SRAM

SDRAM
- Synchronous DRAM
- 특별한(발전된 형태의) DRAM
- 클럭 신호와 동기화된 DRAM
DDR SDRAM
- Double Data Rate SDRAM
- 특별한(발전된 형태의) SDRAM
- 최근 가장 대중적으로 사용하는 RAM
- 대역폭을 넓혀 속도를 빠르게 만든 SDRAM
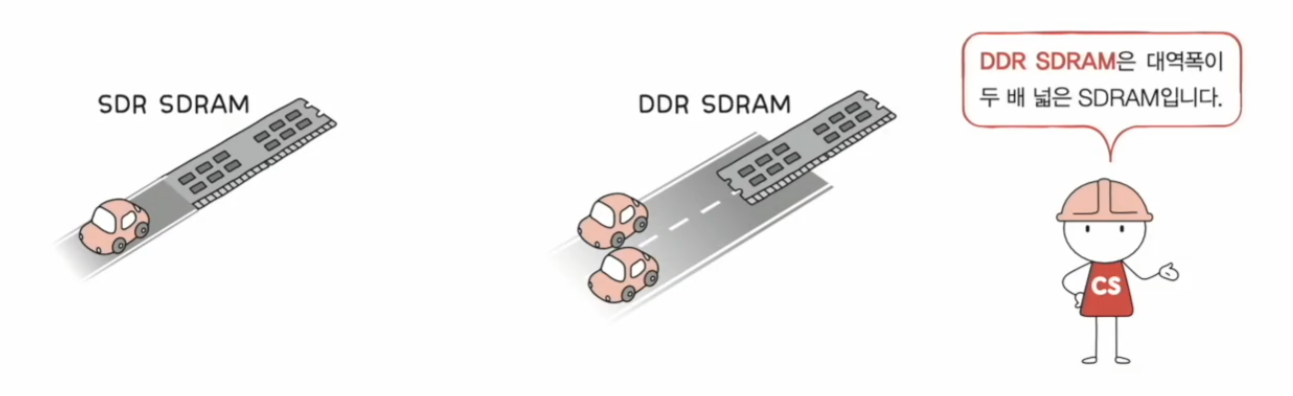

DDR3와 DDR4도 있다. DDR3는 DDR2가 두 개, 즉 길이 8개인 것과 같다. 그리고 DDR4는 DDR3가 두 개인 길이 16개인 것과 같다.
현재 가장 대중적으로 사용되는 것은 DDR4이다. 지 내가 사용하고 있는 컴퓨터도 DDR4를 사용하고 있다.
메모리의 주소 공간

논리 주소와 물리 주소로 주소 공간을 나눈 이유와 논리 주소를 물리 주소로 변환하는 방법을 알아보자
물리 주소와 논리 주소
CPU와 실행 중인 프로그램은 현재 메모리 몇 번지에 무엇이 저장되어 있는지 다 알고 있을까?
그렇지 않다. CPU와 실행 중인 프로그램은 메모리 몇 번지에 무엇이 저장되어 있는지 다 알지 못한다.
왜냐하면 메모리에 저장된 값들은 시시각각 변하기 때문이다.
새롭게 실행되는 프로그램은 새롭게 메모리에 적재되고, 실행이 끝난 프로그램은 메모리에서 삭제된다. 그리고 같은 프로그램을 실행하더라도 실행할 때마다 적재되는 주소는 달라진다.
이런 점을 극복하기 위해 주소 체계를 물리 주소와 논리 주소로 나눈 것이다.
물리 주소
- 메모리 입장에서 바라본 주소
- 말 그대로 정보가 실제로 저장된 하드웨어 상의 주소
논리 주소
- CPU와 실행 중인 프로그램 입장에서 바라본 주소
- 실행 중인 프로글매 각각에게 부여된 0번지부터 시작하는 주소
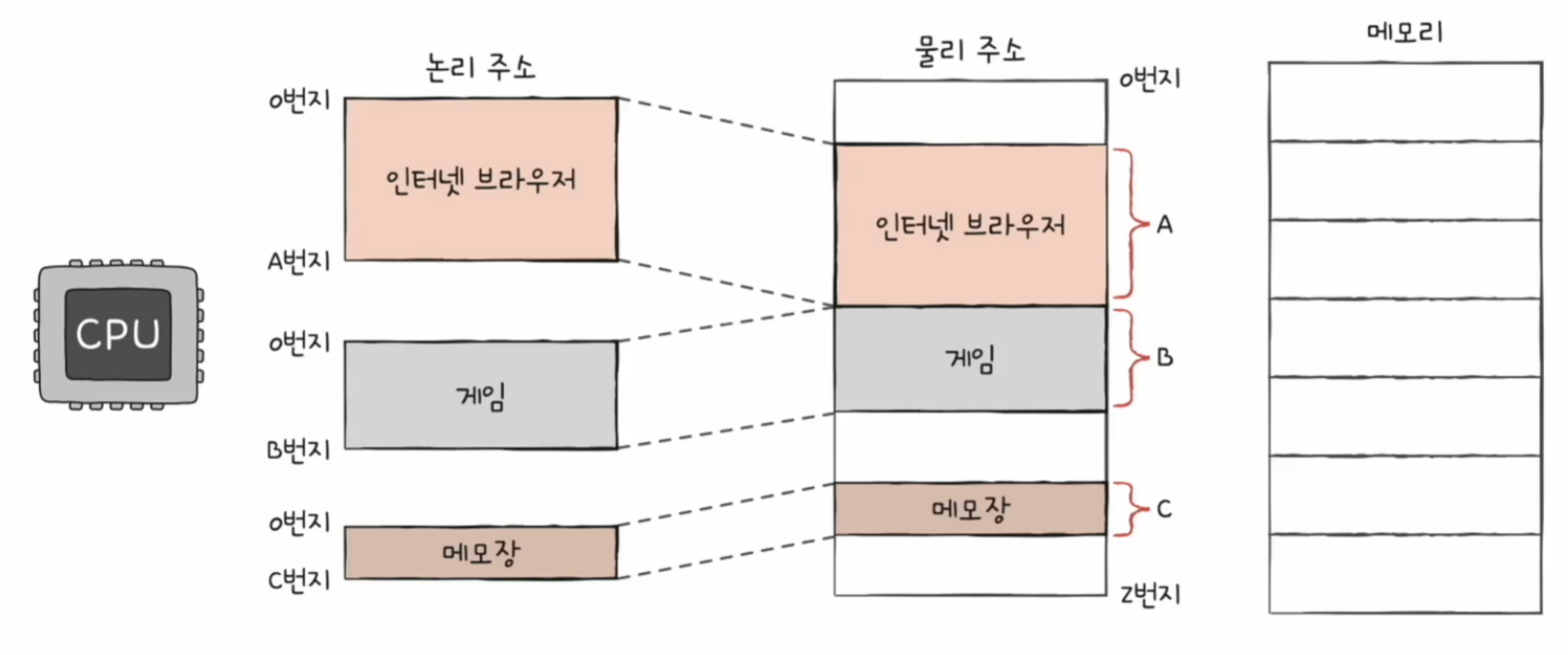
물리 주소와 논리 주소의 변환

논리 주소에는 동일한 주소가 여러 개 존재할 수 있다. 하지만 물리 주소에는 그럴 수 없다. 그래서 CPU가 메모리와 상호작용을 하려면 논리 주소를 물리 주소로 변환하는 과정이 필요하다.
주소 변환은 MMU(메모리 관리 장치)라는 하드웨어에 의해 변환된다.

CPU가 이해하고 실행하는 주소는 모두 논리 주소이다. 논리 주소를 주소 버스를 통해 실제 메모리와 주고받을 때에는 항상 MMU를 거치게 된다.
MMU는 논리 주소와 베이스 레지스터(프로그램의 기준(시작) 주소) 값을 더하여 논리 주소를 물리 주소로 변환한다. 논리 주소는 실제로 저장된 프로그램으로부터 얼마나 떨어져 있느냐에 해당하는 정보라고 생각할 수 있다.


베이스 레지스터는 프로그램의 가장 작은 물리 주소를 저장하는 셈이고, 논리 주소는 프로그램의 시작점으로부터 떨어진 거리인 셈이다.
메모리 보호
다른 프로그램의 영역을 침범하는 명령어는 실행해서는 안된다.

위 명령어는 실행되어도 안전할까?
베이스 레지스터에는 1000번지가 담겨 있다. 논리 주소 1500번지라고 하면 물리 주소로는 2500번지를 가리키게 된다. 그래서 인터넷 브라우저에 숫자 100을 저장하게 된다. 결국 다른 프로그램의 영역을 침범한 것이 된다.

마찬가지로 위 명령어도 안전하지 않다. 인터넷 브라우저의 논리 주소를 벗어난 명령어이기 때문이다. 이 명령어가 실행될 경우 게임의 데이터가 삭제될 것이다.
따라서 메모리를 보호하는 방법이 필요하게 되었다. 어떤 명령어가 다른 프로그램의 영역을 침범하지 않도록 메모리를 보호해야 한다.
한계 레지스터를 사용하여 메모리를 보호할 수 있다.
한계 레지스터
- 프로그램의 영역을 침범할 수 있는 명령어의 실행을 막음
- 베이스 레지스터가 실행 중인 프로그램의 가장 작은 물리 주소를 저장한다면, 한계 레지스터는 논리 주소의 최대 크기를 저장
- 베이스 레지스터 값 <= 프로그램의 물리 주소 범위 < 베이스 레지스터 + 한계 레지스터 값
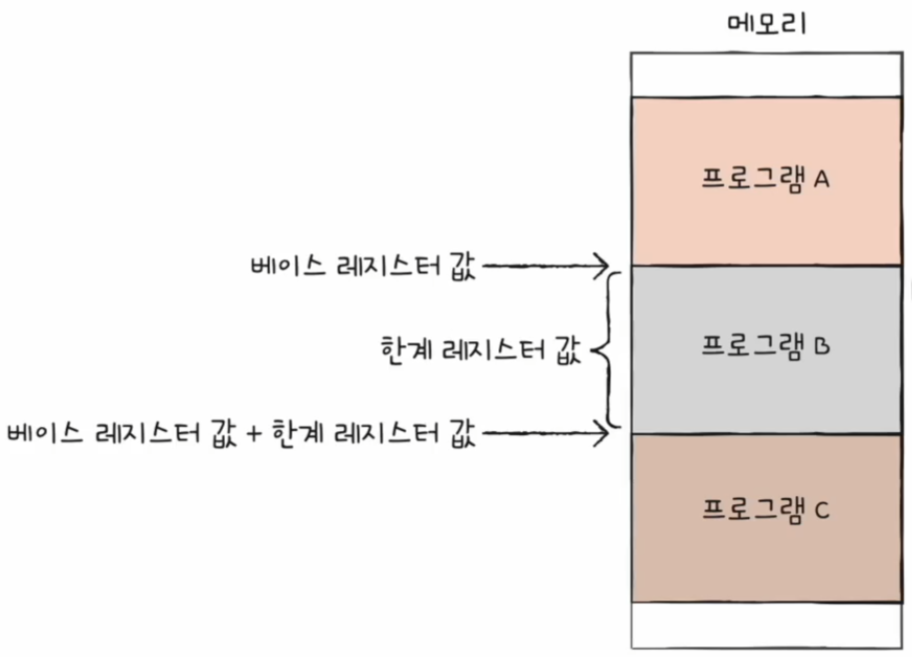
베이스 레지스터에 100, 한계 레지스터에 150이 저장되어 있다고 가정해 보자
이 경우 물리 주소 시작점이 100번지, 프로그램의 크기(논리 주소의 최대 크기)는 150이다.
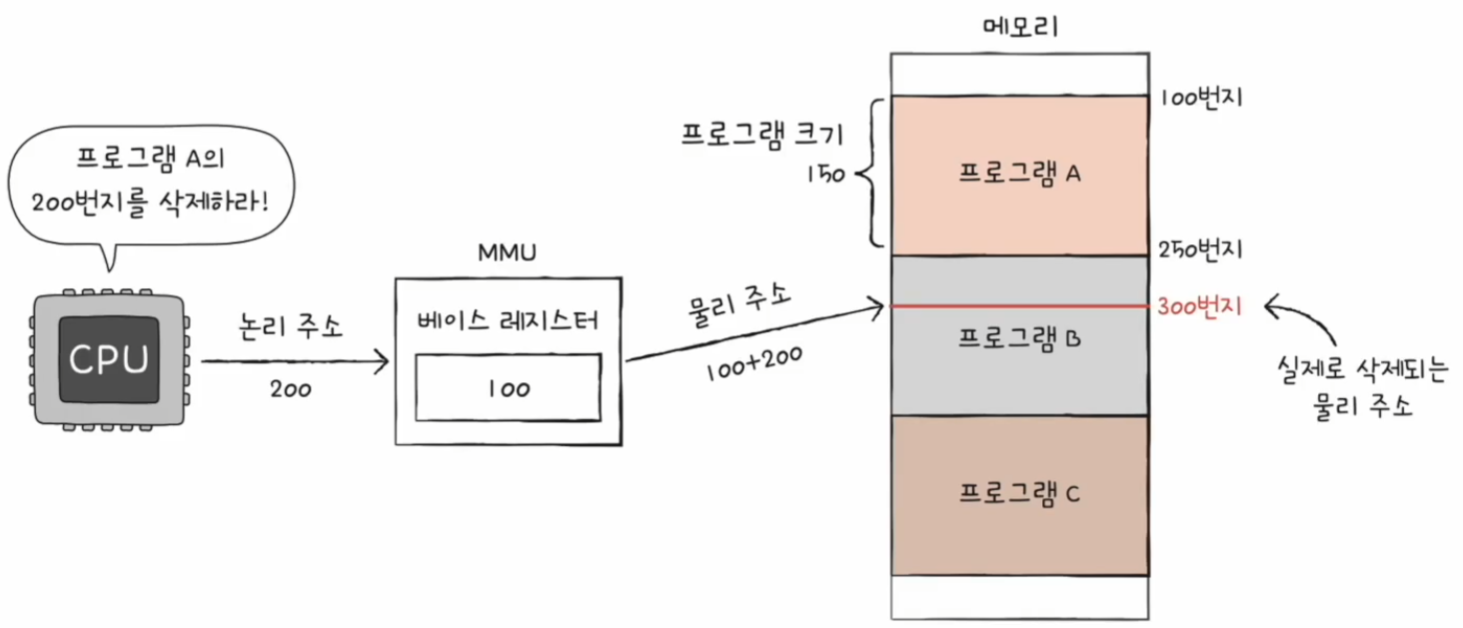
한계 레지스터를 통해 이런 상황을 막을 수 있다.
정리하면 CPU는 메모리에 접근하기 전에 접근하고자 하는 논리 주소가 한계 레지스터보다 작은 지를 항상 검사한다.
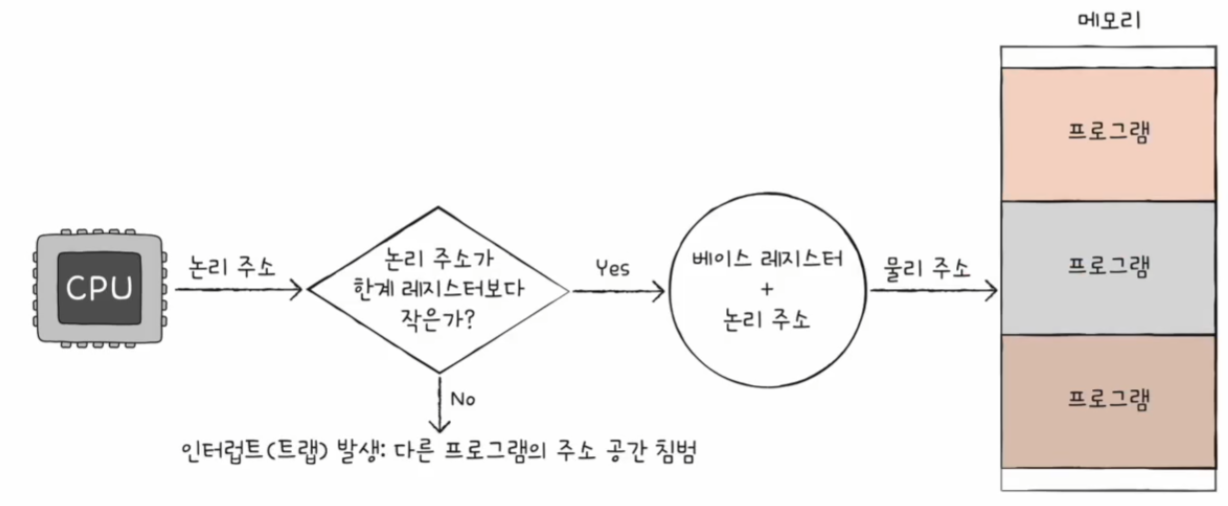
이를 통해, 실행 중인 프로그램의 독립적인 실행 공간을 확보하고 하나의 프로그램이 다른 프로그램을 침범하지 못하게 보호한다.
캐시 메모리
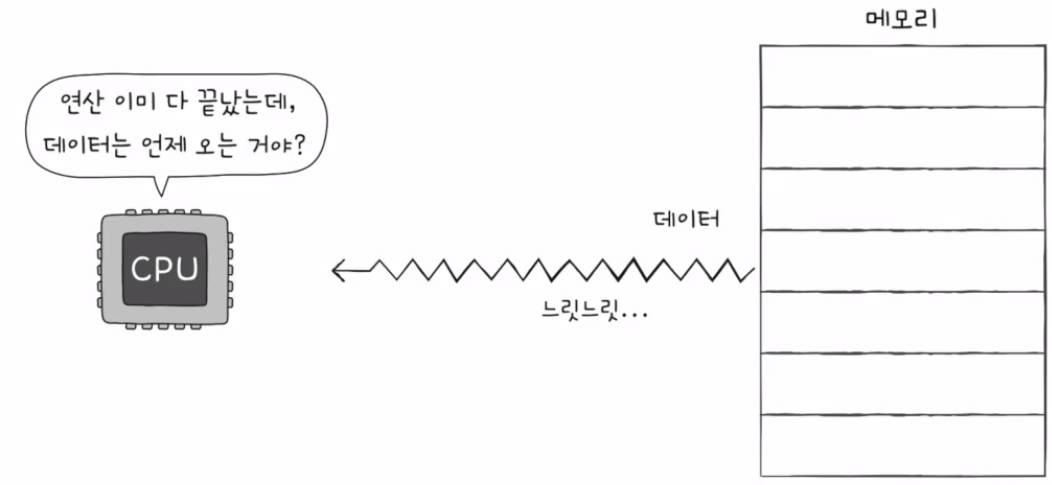
CPU가 메모리에 접근하는 시간은 CPU 연산 속도보다 느리다.
캐시 메모리에 대해 이해하려면 먼저 저장 장치 계층 구조라는 개념에 대해 이해를 해야 한다.
저장 장치 계층 구조
- CPU와 가까운 저장 장치는 빠르고, 멀리 있는 저장 장치는 느리다.
- 속도가 빠른 저장 장치는 저장 용량이 적고, 가격이 비싸다.
레지스터 vs 메모리(RAM) vs USB 메모리에 대해 비교해 보자
CPU와 가장 가까운 레지스터는 일반적으로 RAM보다 용량은 적지만 접근 시간이 가장 빠르고 가격이 비싸다.
USB 메모리보다 CPU에 더 가까운 RAM은 USB 메모리보다 접근 시간이 훨씬 빠르지만 같은 용량 대비 가격이 훨씬 비싸다.
낮은 가격대의 대용량 저장 장치를 원한다면 느린 속도는 감수해야 하고, 빠른 속도의 저장 장치를 원한다면 작은 용량과 비싼 가격을 감수해야 한다.
저장 장치들은 'CPU에 얼마나 가까운가'를 기준으로 계층적으로 나타낼 수 있다.

저장 장치 계층 구조는 memory hierarchy이다. 여기서 memory는 RAM이 아닌 일반적인 저장 장치를 의미한다.
캐시 메모리
- CPU와 메모리 사이에 위치한 레지스터보다 용량이 크고 메모리보다 빠른 SRAM 기반의 저장 장치
- CPU의 연산 속도와 메모리 접근 속도의 차이를 조금이나마 줄이기 위해 탄생
- 'CPU가 매번 메모리에 왔다 갔다 하는 건 시간이 오래 걸리니, 메모리에서 CPU가 사용할 일부 데이터를 미리 캐시 메모리로 가지고 와서 쓰자'
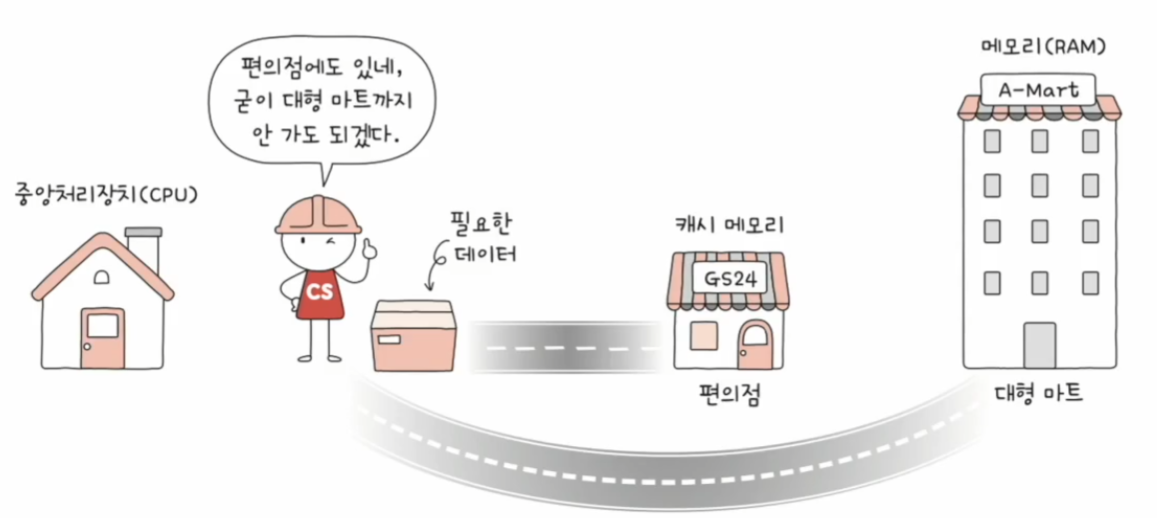
메모리에 접근하는 것을 물건을 사러 가는 것, 메모리를 물건은 많지만 집과는 멀리 떨어져 있어 왕복이 오래 걸리는 대형 마트, 캐시 메모리를 물건이 많지는 않아도 집과 가까이 있는 편의점으로 비유해 보면 아래 그림과 같다.
캐시 메모리까지 반영한 저장 장치 계층 구조는 아래와 같다.

캐시 메모리는 계층적으로 구성할 수 있다. (L1 - L2 - L3 캐시)
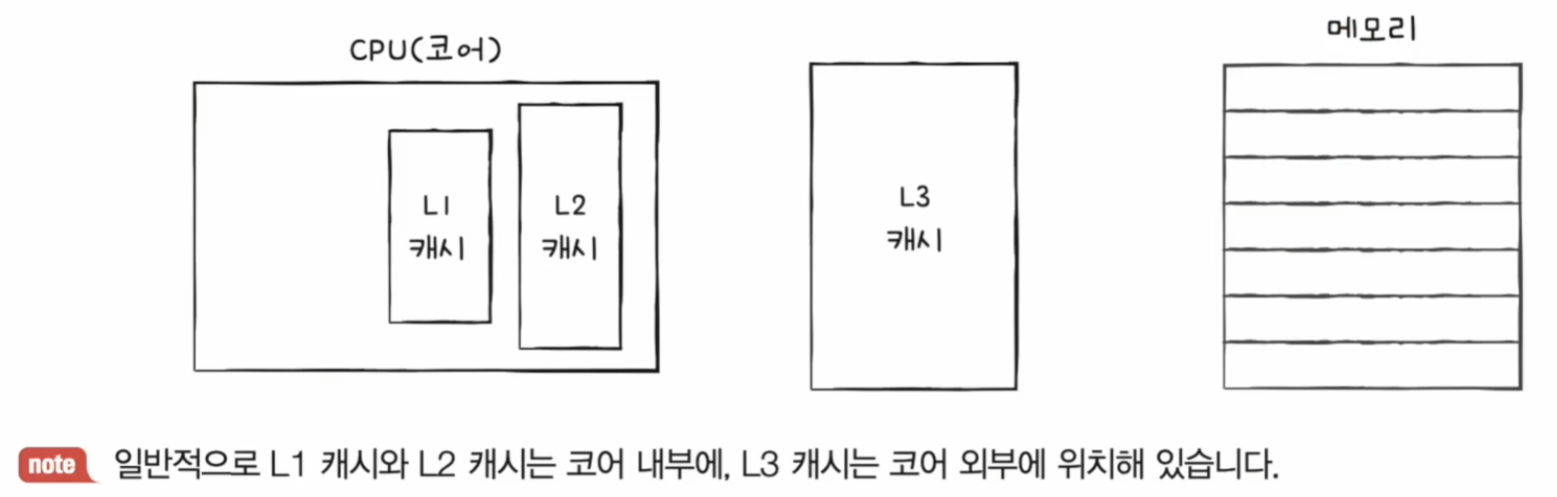

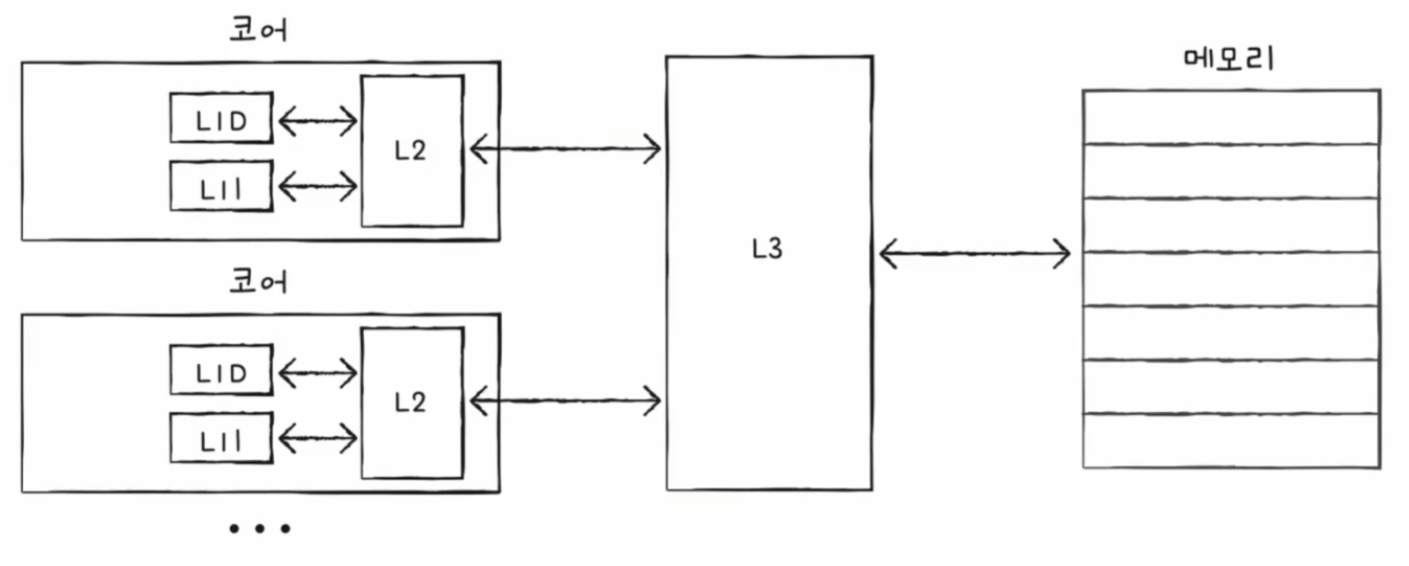
L1 캐시를 조금이라도 더 빠르게 만들기 위해 명령어만을 담고 있는 L1 캐시, 데이터만을 담고 있는 L1 캐시, 이런 식으로 분리하기도 한다.
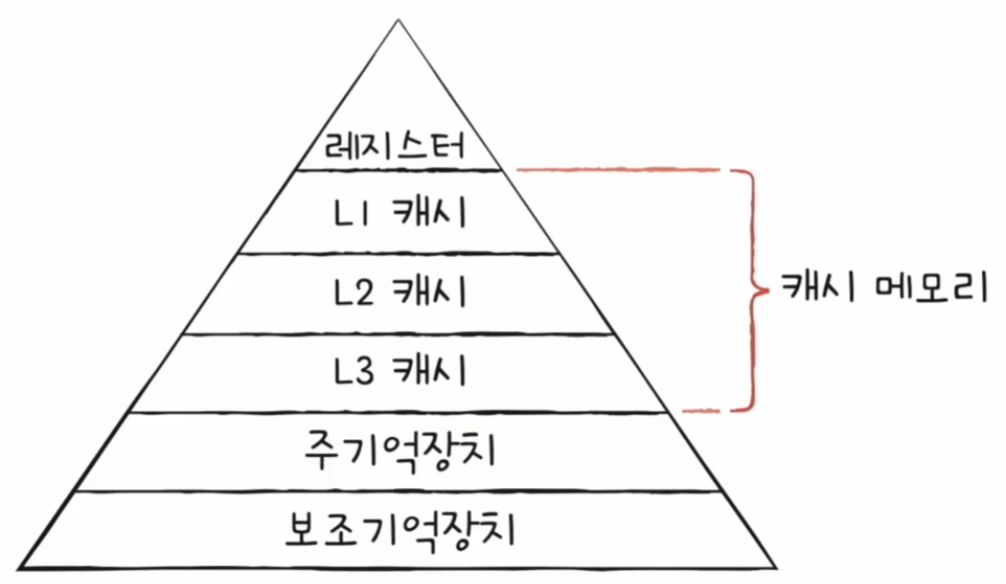
계층적 캐시 메모리까지 반영한 저장 장치 계층 구조는 아래와 같다.
참조 지역성의 원리
캐시 메모리는 메모리보다 용량이 적어 메모리의 모든 내용을 저장할 수 없다.
따라서 CPU가 자주 사용할 법한 내용을 예측하여 저장해야 한다.
이 예측이 맞을 경우(CPU가 캐시 메모리에 저장된 값을 활용할 경우)를 '캐시 히트'라고 한다.

반면 예측이 틀렸을 경우 (CPU가 메모리에 접근해야 하는 경우)를 캐시 미스라고 한다.

✔️ 캐시 적중률
캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수)
메모리의 접근 횟수와 시간을 줄이고 빠르게 CPU가 원하는 데이터를 가져오기 위해서는 캐시 적중률을 높여야 한다. 즉 CPU가 사용할 법한 데이터를 잘 예측해야 한다.
CPU가 사용할 법한 데이터를 예측하는 방법이 참조 지역성의 원리이다.
참조 지역성의 원리
CPU가 메모리에 접근할 때의 주된 경향을 바탕으로 만들어진 원리이다.
- CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향이 있다.
- CPU는 접근한 메모리 공간 근처를 접근하려는 경향이 있다.
최근에 접근했던 메모리 공간에 다시 접근하려는 경향
#include <stdio.h>
int main(void) {
int num = 2;
for (int i = 1; i <= 9; i++)
printf("%d X %d = %d\n", num, i, num * i);
return 0;
}위 코드를 실행할 때 num이라는 주소 공간에 여러 번 접근하는 경향이 보인다. 이런 식으로 최근에 접근했던 메모리 공간에 다시 접근하려는 경향이 있다.
접근한 메모리 공간 근처를 접근하려는 경향 (공간 지역성)